Welcome
Welcome to Revela's documentation! Revela is a developer friendly machine learning (ML) model monitoring API. Our goal is to make ML monitoring adoption as easy as possible for teams large and small.
⚡ Fast track to our Quick Start Guide or continue reading.
Intro to ML Monitoring
Monitoring ML models in production is said to be the final mile of the ML lifecycle and is often uncharted territory for teams. ML models are only as good as the data they are trained on and one thing you can guarantee is that once a model is deployed to production, it will eventually encounter data that is statistically different from its training data. This is broadly categorized as drift; it can be caused by changes in the real-world environment, malfunctioning data sources, or even our own evolving definition of a concept. This is when ML becomes unpredictable, or in some cases even harmful.
How Revela Works
With Revela, keep track of your production model's performance by continuously monitoring the input data, the model’s predictions, and the ground truth for each inference (if you can get it). Revela will calculate your configured metrics on this data so you can see exactly what is going on. If your model's behaviour becomes abnormal, you will be alerted with concise information about what has changed, freeing you up from constantly having to keep an eye on your deployed models. Being API-first, Revela conveniently integrates into your favorite data visualization tools. Check out this live demo from Revela’s lead architect Zev.
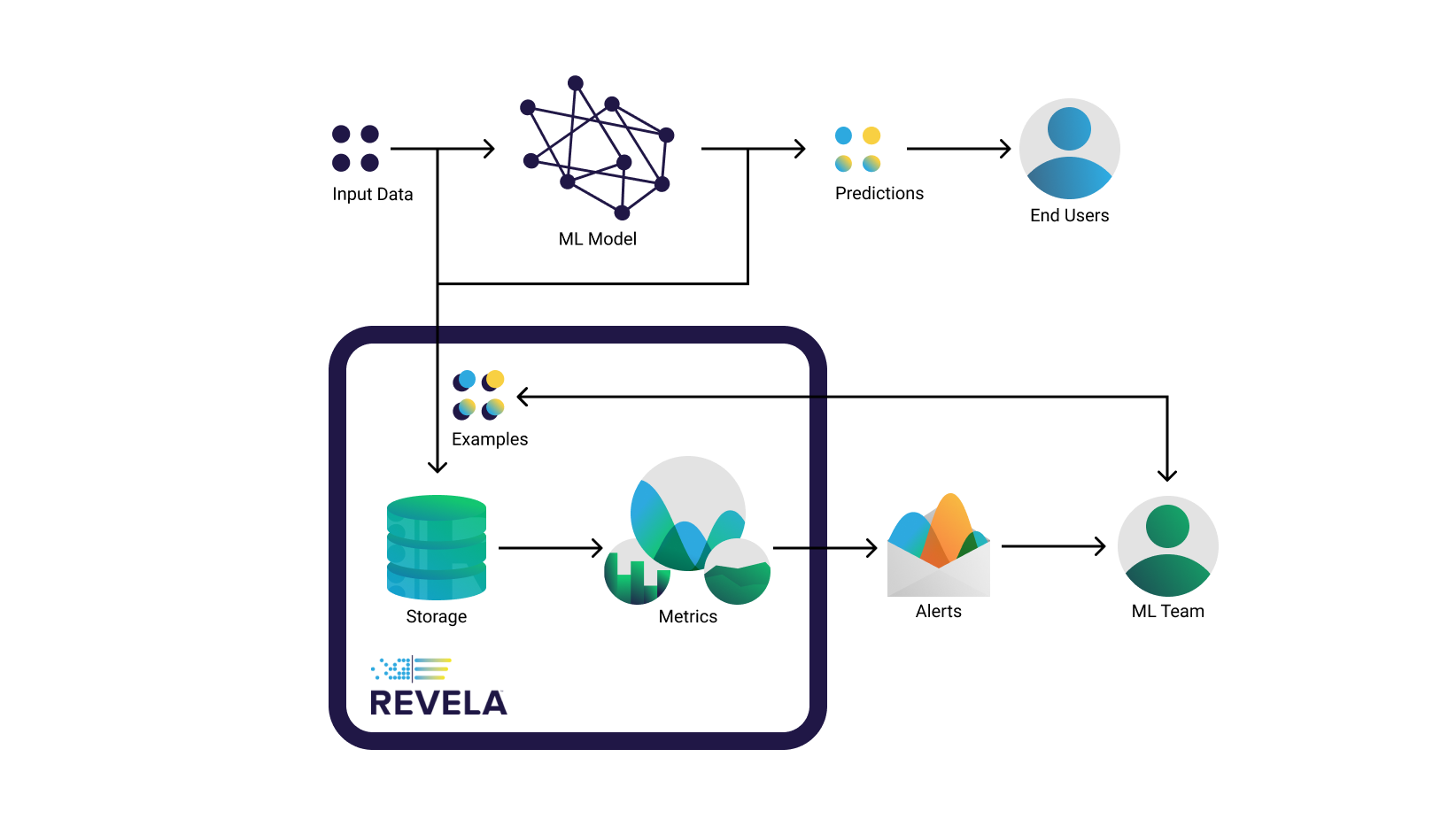
Getting Started with a Free Trial
Start using Revela today by following our quick start guide and getting set up on our free cloud-hosted version.
To work with Revela, you need the URL of an instance of the Revela API. For the trial you will use revela.app/api/.
For a thorough technical explanation of Revela's main concepts, follow the links in the sidebar to the left. We recommend starting with the models section.
Installation
You do not need to install anything to use this service if you intend on using our free cloud-hosted version found at revela.app/api/.
Contact us for details and pricing for deploying your own instance of Revela. We provide support for fully isolated self-hosted deployments on Kubernetes.
Revela is simple to use with any HTTP client. You will need an HTTP client to interact with the Revela API, and many popular languages have them built in. In python urllib.request is built in, but we recommend httpx. In JavaScript on the web fetch is built in, and we recommend using it or axios. For technical exploration, Kong's Insomnia HTTP client is also great.
For convenience, we’ll be providing a client library in the future.
Data capture
The Revela API works by capturing and storing your models' input data and predictions. By using the Revela API during your trial, you acknowledge that all data used to run inferences will be securely stored on our cloud server. You can inspect your data and configure our system to compute metrics from it. You can delete your data at any time by deleting the parent model or deployment from our system.
If you have confidential data that you cannot send over the internet to the Revela-hosted API, no problem. We built Revela to be easily deployable on your own infrastructure. Contact us to learn more about our on-premise enterprise edition.
Glossary
Below is a summarized list of concepts which are important to know to effectively use the Revela ML monitoring API.
| Concept | Description |
|---|---|
| Model | Revela's representation of the ML model you want to monitor. |
| Deployment | Revela's representation of a single ML model deployment. |
| Example | A single inference data point (input data, prediction, and (optionally) actual). |
| Actuals | Ground truth of a model's predictions. |
Feedback
Is something in this documentation unclear? Do you have any suggestions for our product or these docs? We'd welcome your feedback! Send us an email at support@revela.io.